F5 rSeries Planning Guide Source |
rSeries High Availability¶
Tenant Level HA Across Appliances¶
F5 recommends configuring dual rSeries appliances with identically configured tenants and maintaining HA relationships at the tenant level as seen below. This mimics the iSeries HA behavior that is typically configured between vCMP guests. There is no redundancy between rSeries appliances at the F5OS platform layer. The appliances themselves are unaware of the other appliance and there is no HA communication at this level, it’s the tenants that form the HA relationship. rSeries does not support tenant HA within the same appliance, it must be configured between tenants in separate appliances. Direct (hard wired) HA modes are not supported even though there is a port for this on each rSeries unit it is unused. HA must use network level failover configurations using Device Service Clusters or other network-based failovers.
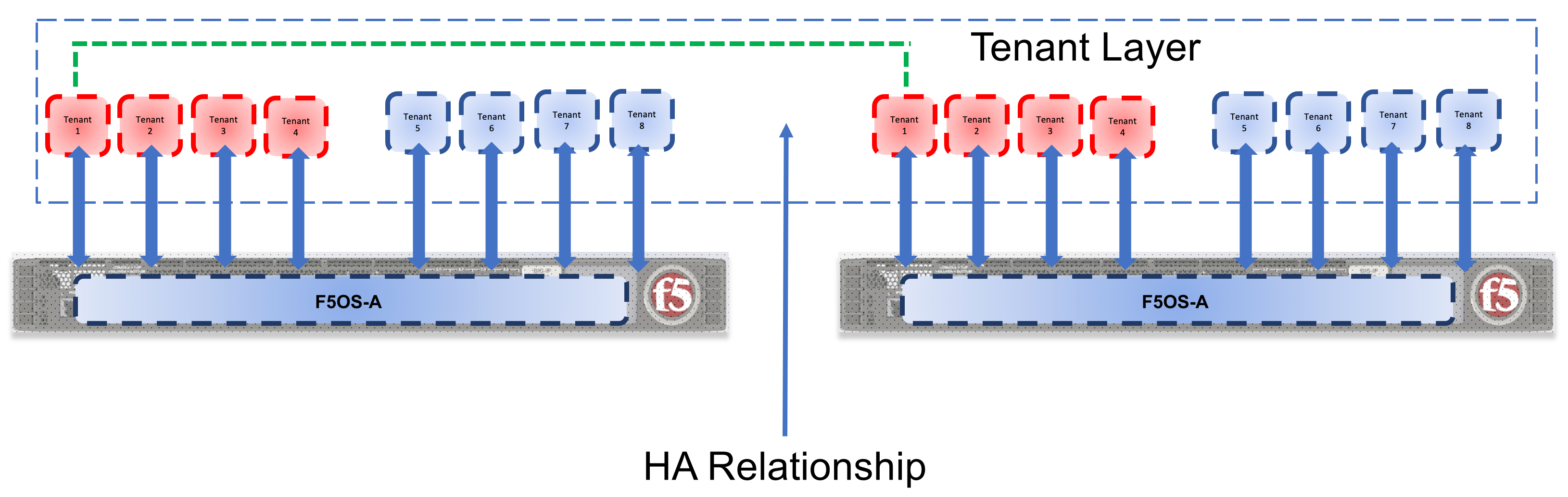
Tenants on different appliances should have the same number of vCPUs and identical memory configuration. HA interconnection VLANs would be configured between appliances, and then tenants would configure HA just as is the case with vCMP guest HA relationships. Below is an example of two rSeries appliances each with their own HA interconnects and in-band networking. Some customers may prefer not to dedicate links for the HA interconnect, but the preferred method is to have dedicated links that will carry HA / mirroring related traffic. In the diagram below a LAG is created on each rSeries unit and it is dual homed to upstream layer2 switches running in a VPC style mode where they appear as one virtual switch. There are different variations on this design. The one below has a dedicated LAG for HA Interconnect traffic, this isolates mirroring and other HA traffic to run over its own set of interfaces, providing better isolation and performance. This is not mandatory but is preferred in many environments.
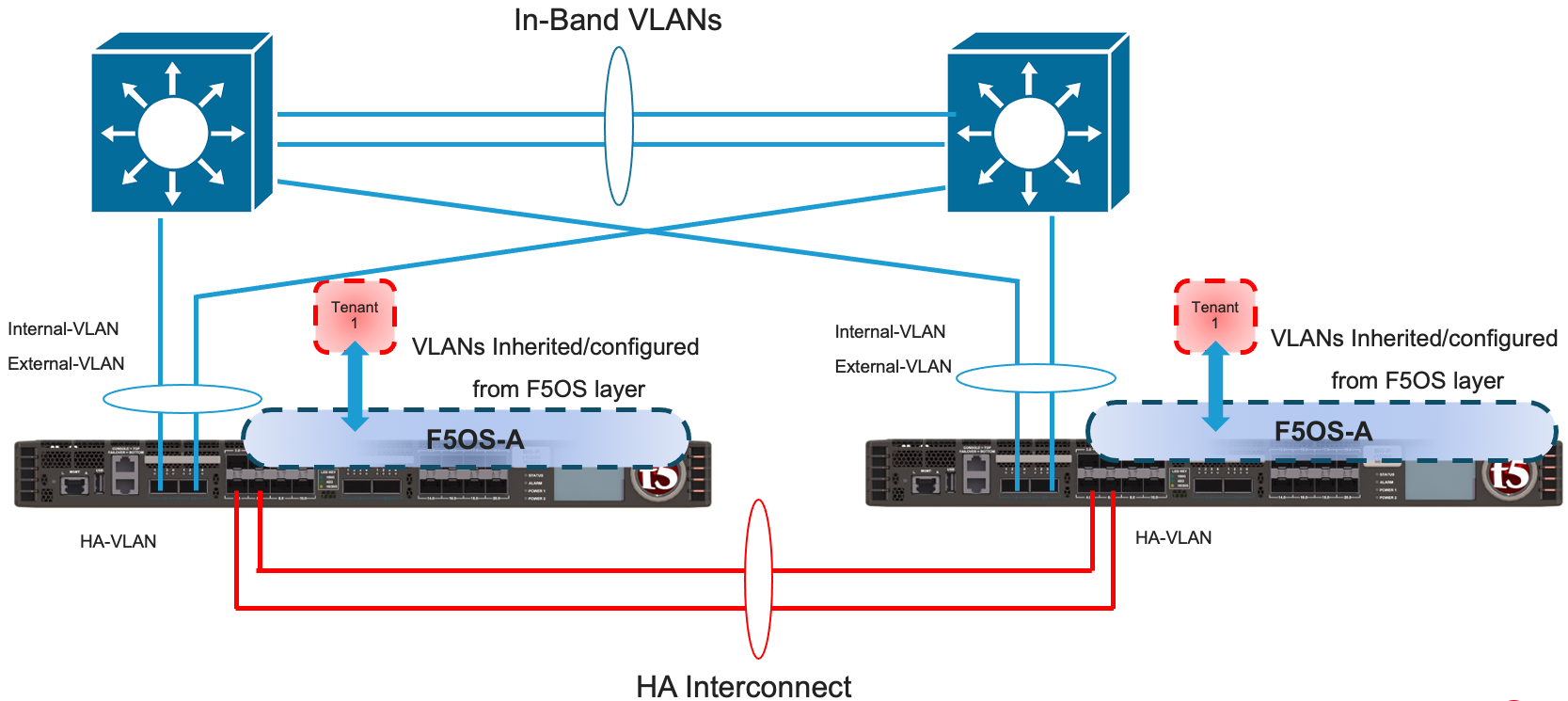
In some customer environments they may not want to run the HA VLANs over a dedicated LAG between the rSeries units. In this case the HA VLAN’s are running over the in-band LAG’s going to the upstream layer2 switches. This deployment mode may use less ports on rSeries, but now HA traffic and some heartbeat traffic is intermingled on the same links as in-band traffic and under certain conditions might not get prioritized in the L2 switching infrastructure if the network is saturated. This might not be an issue for most customers, but in heavily utilized environments this is something that should be considered. Depending on the amount and type of mirroring, you are also adding additional latency between the HA pairs, and this will increase the time for acknowledgements to be sent and received and ultimately for a transaction to be acknowledged to a client.
If VPC style interconnects are not used, then the same concepts from above are used but slightly altered. In the first case LAGs are not dual homed due to lack of VPC support and instead are configured as point-to-point LAGs between one rSeries device and one upstream layer2 switch. Again, a dedicated HA link is optional but preferred.
This deployment mode is identical to the one above but lacks the dedicated HA interconnect LAG. This will have the same caveats as listed in the VPC with no dedicated LAG design.

Tenant Level HA within the Same Appliance¶
rSeries does not support configuring HA relationships between tenants within the same appliance. Depending on what failover behavior you want, you can have the tenant run with less capacity if certain failures occur or fail over to the tenant in the other appliance. This is controlled within the tenant itself, just like HA failover was configured inside a vCMP guest. HA Groups allow an administrator to fail over based on pool, trunk, or blade (For VELOS/VIPRION systems) availability.
Below is an example of a “SuperVIP” tenant that spans all available vCPUs. Each rSeries appliance will have one static out-of-band management IP address. Each tenant will require an out-of-band management address on the same network, and optional in-band self-IP addresses can be added within the tenant.
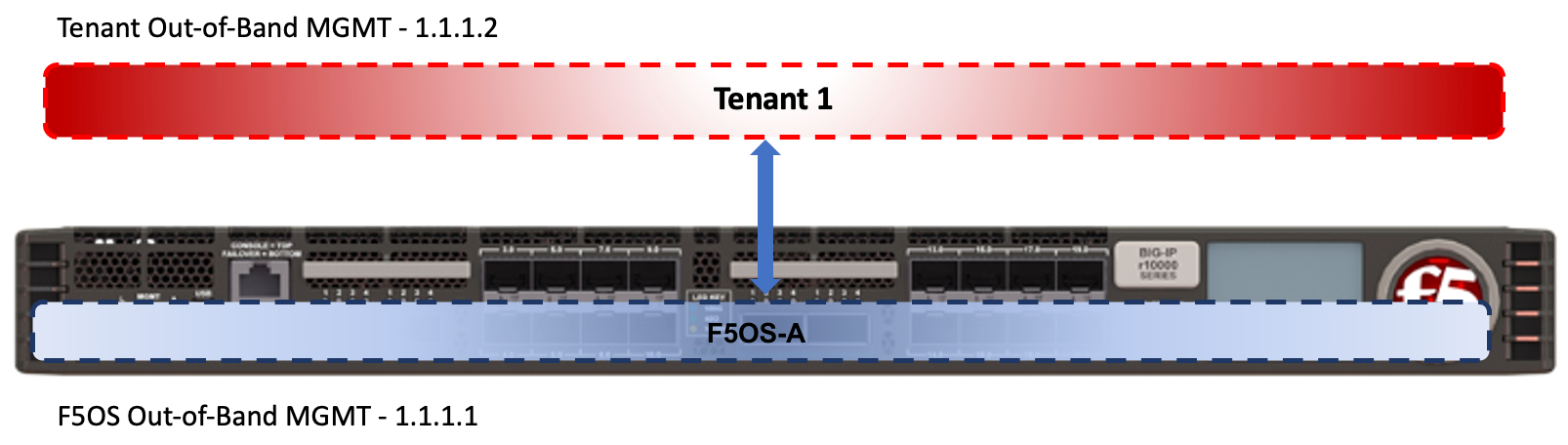
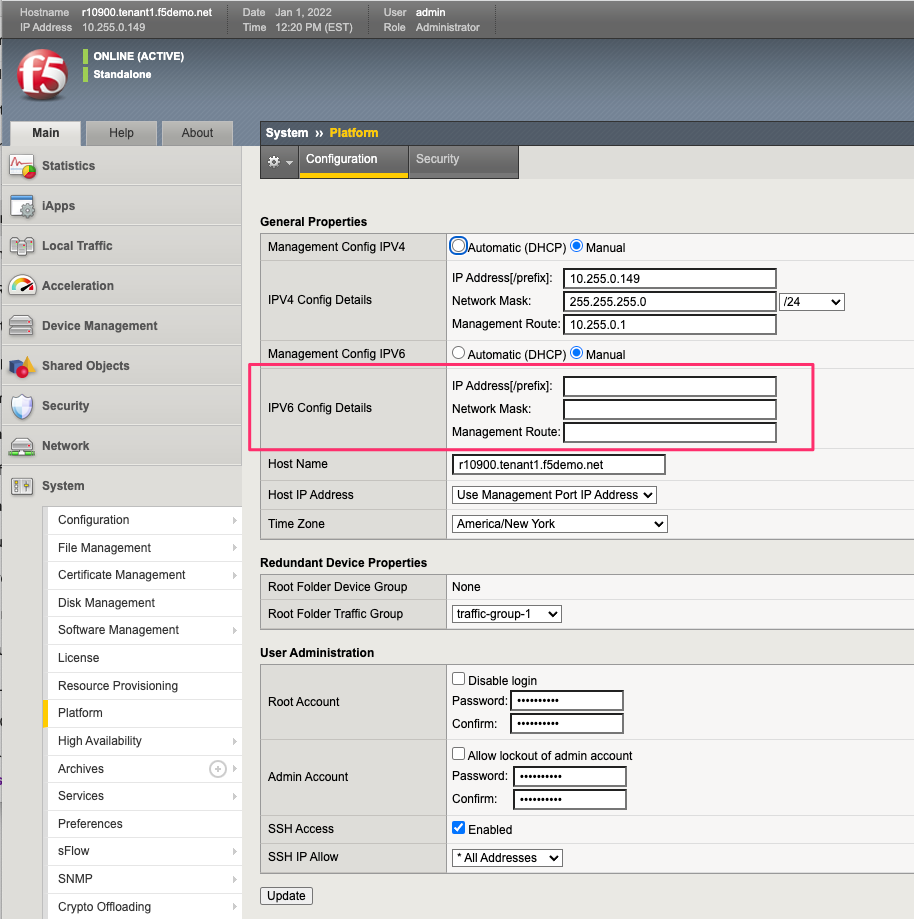
Inside the tenant, Cluster Member IP Address will not be needed as they are for chassis-based systems such as VIPRION or VELOS. If using IPv4 & IPv6 (dual stack management) then IPv6 management addresses can be configured.
For planning purposes, a single large tenant “SuperVip” spanning all available vCPUs would require 2 out-of-band management IP addresses for each appliance. One for the F5OS platform layer, and one for the tenant itself. In-band Self-IP & Virtual addresses are not included in this calculation.
| IP Addresses Required | Single Chassis | HA Environment |
|---|---|---|
| rSeries Out-of-Band Mgmt | 1 | x2 for HA = 2 |
| Tenant Out-of-Band Mgmt | 1 per Tenant | x2 for HA = 2 |
| Total | 2 (+1 for each additional tenant) | x2 for HA = 4 |
HA Group Configuration to Control Tenant Failover¶
An active tenant will naturally failover to the standby tenant in another rSeries appliance if the tenant is not healthy and the standby detects it has failed. Ideally you should also configure HA Groups or some other mechanism within the tenant to detect external conditions that you will want to trigger a failover for. As an example, HA groups can monitor blades (in the VELOS/VIPRION chassis), and failover if a minimum number of active blades is not met. For rSeries you can monitor pool member reachability or Trunk (Link Aggregation Group) availability to trigger failover.